NeurIPS 22
It’s @NeurIPSConf time! pic.twitter.com/8xrKYQ6hYf
— Paul @NeurIPS2022 (@PaulGavrikov) November 28, 2022
It’s a wrap! Time to go home after many fruitful discussions at #NeurIPS2022
— Paul @NeurIPS2022 (@PaulGavrikov) December 4, 2022
Feel free to check out our papers: Robustness & Overcofidence: https://t.co/2ecMJ0iYzk
Medical Imaging CNNs: https://t.co/3kPeREIvUa pic.twitter.com/t1XUwSxQWT
Full Paper
Trading off Image Quality for Robustness is not Necessary with Regularized Deterministic Autoencoders
Amrutha Saseendran, Kathrin Skubch, Margret Keuper
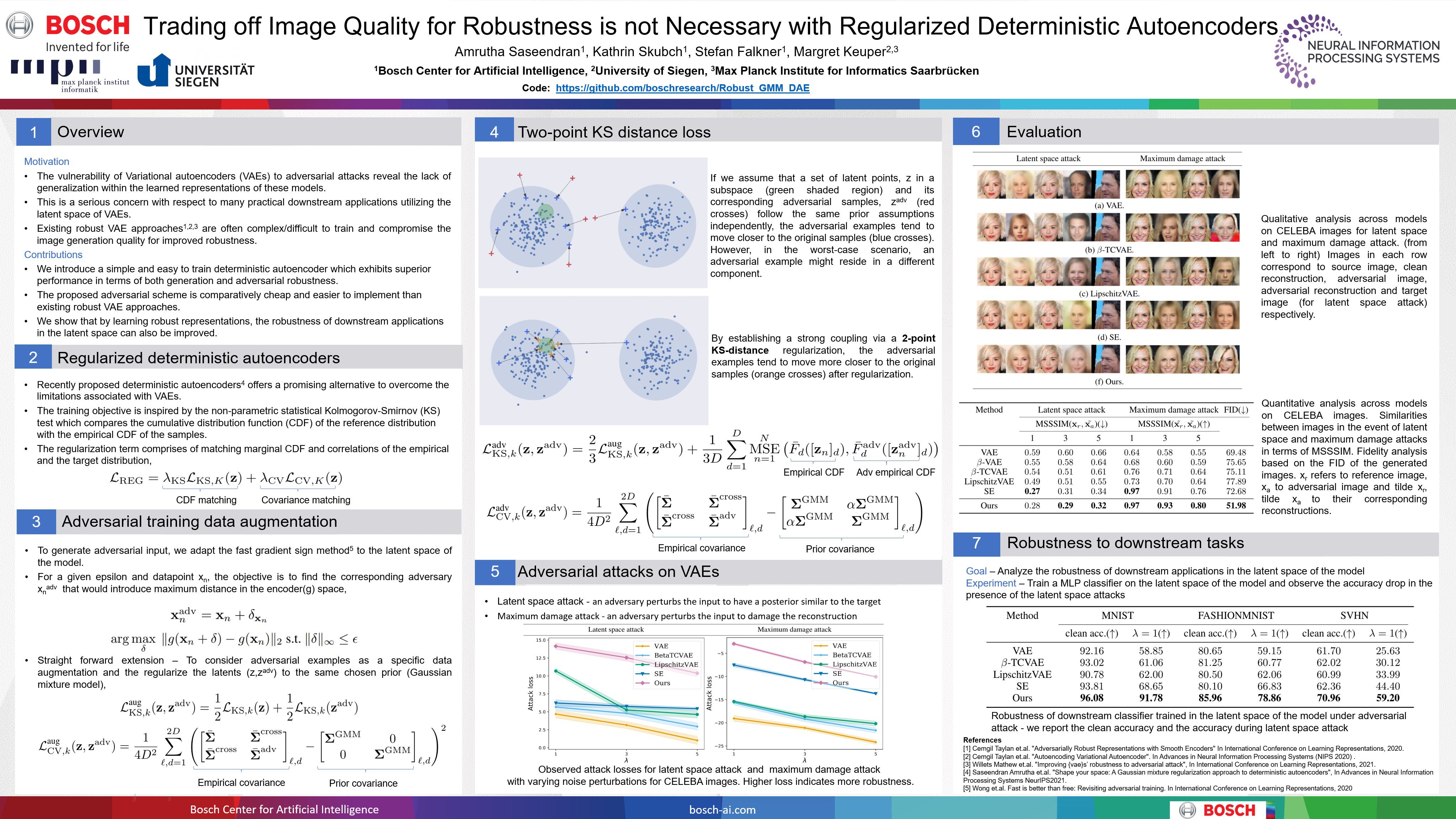
The susceptibility of Variational Autoencoders (VAEs) to adversarial attacks indicates the necessity to evaluate the robustness of the learned representations along with the generation performance. The vulnerability of VAEs has been attributed to the limitations associated with their variational formulation. Deterministic autoencoders could overcome the practical limitations associated with VAEs and offer a promising alternative for image generation applications. In this work, we propose an adversarially robust deterministic autoencoder with superior performance in terms of both generation and robustness of the learned representations. We introduce a regularization scheme to incorporate adversarially perturbed data points to the training pipeline without increasing the computational complexity or compromising the generation fidelity when compared to the robust VAEs by leveraging a loss based on the two-point Kolmogorov–Smirnov test between representations. We conduct extensive experimental studies on popular image benchmark datasets to quantify the robustness of the proposed approach based on the adversarial attacks targeted at VAEs. Our empirical findings show that the proposed method achieves significant performance in both robustness and fidelity when compared to the robust VAE models.
Robust Models are less Over-Confident
Julia Grabinski, Paul Gavrikov, Janis Keuper, Margret Keuper
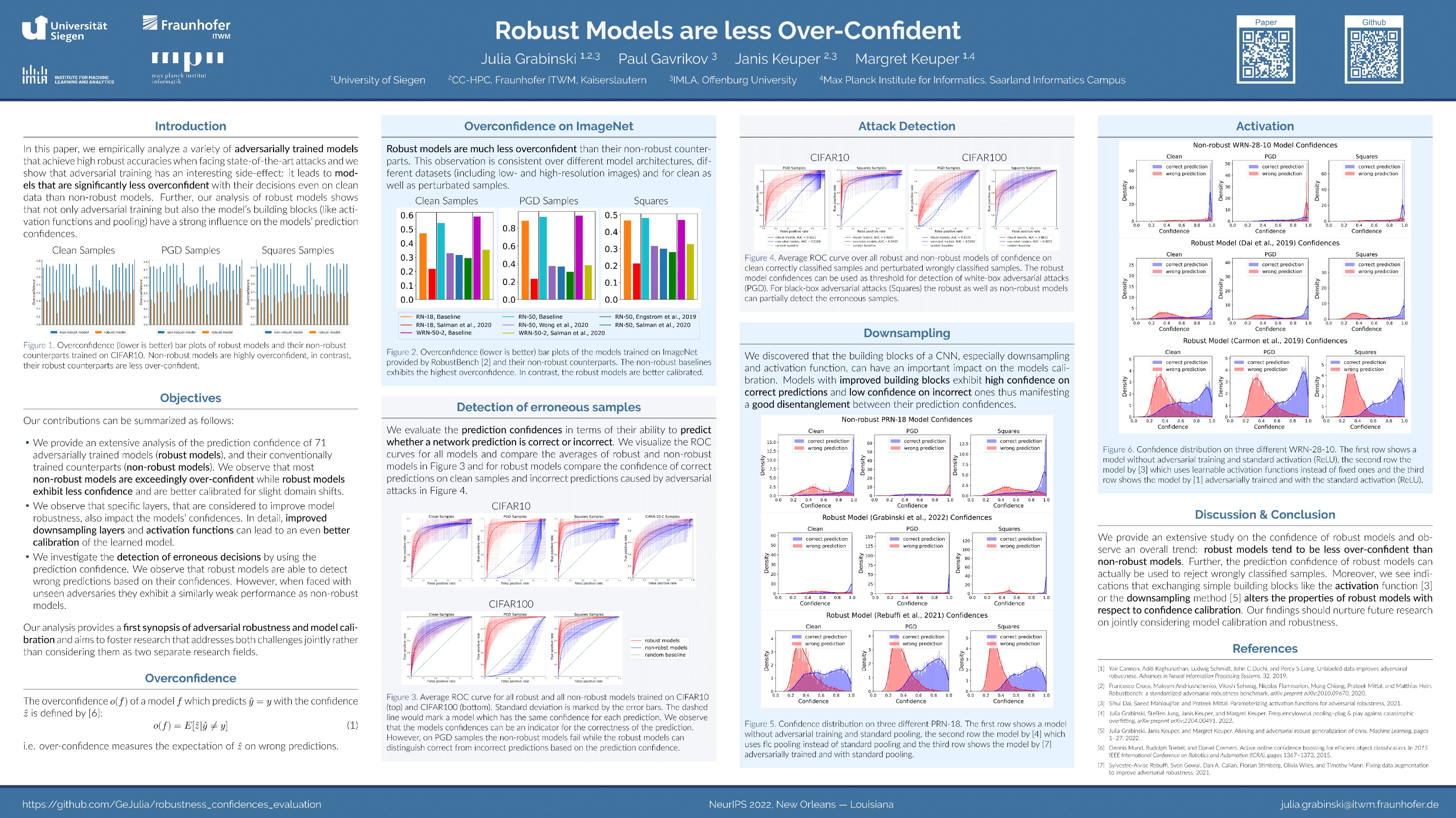
Despite the success of convolutional neural networks (CNNs) in many academic benchmarks for computer vision tasks, their application in the real-world is still facing fundamental challenges. One of these open problems is the inherent lack of robustness, unveiled by the striking effectiveness of adversarial attacks. Current attack methods are able to manipulate the network’s prediction by adding specific but small amounts of noise to the input. In turn, adversarial training (AT) aims to achieve robustness against such attacks and ideally a better model generalization ability by including adversarial samples in the trainingset. However, an in-depth analysis of the resulting robust models beyond adversarial robustness is still pending. In this paper, we empirically analyze a variety of adversarially trained models that achieve high robust accuracies when facing state-of-the-art attacks and we show that AT has an interesting side-effect: it leads to models that are significantly less overconfident with their decisions, even on clean data than non-robust models. Further, our analysis of robust models shows that not only AT but also the model’s building blocks (like activation functions and pooling) have a strong influence on the models’ prediction confidences. PDF
Workshop Paper
Had a great time at the #medneurips workshop today presenting „Does Medical Imaging learn different Convolution Filters?“ https://t.co/3kPeREZyWa pic.twitter.com/5rdHmszYHT
— Paul @NeurIPS2022 (@PaulGavrikov) December 2, 2022
MedNeurIPS Workshop: Does Medical Imaging learn different Convolution Filters?
Paul Gavrikov, Janis Keuper

Recent work has investigated the distributions of learned convolution filters through a large-scale study containing hundreds of heterogeneous image models. Surprisingly, on average, the distributions only show minor drifts in comparisons of various studied dimensions including the learned task, image domain, or dataset. However, among the studied image domains, medical imaging models appeared to show significant outliers through “spikey” distributions, and, therefore, learn clusters of highly specific filters different from other domains. Following this observation, we study the collected medical imaging models in more detail. We show that instead of fundamental differences, the outliers are due to specific processing in some architectures. Quite the contrary, for standardized architectures, we find that models trained on medical data do not significantly differ in their filter distributions from similar architectures trained on data from other domains. Our conclusions reinforce previous hypotheses stating that pre-training of imaging models can be done with any kind of diverse image data.
Workshop on Distribution Shifts: Connecting Methods and Applications
Patrick Müller, Alexander Braun, Margret Keuper
Image classification is a long-standing task in computer vision with deep neural 1 networks (DNN) producing excellent results on various challenges. However, they 2 are required not only to perform highly accurate on benchmarks such as ImageNet, 3 but also to robustly handle images in adverse conditions, such as modified light-4 ing, sharpness, weather conditions and image compression. Various benchmarks 5 aimed to measure robustness show that neural networks perform differently well 6 under distribution shifts. While datasets such as ImageNet-C model for example 7 common corruptions such as blur and adverse weather conditions, we argue that 8 the properties of the optical system and the potentially resulting complex lens blur 9 are insufficiently well studied in the literature. This study evaluates the impact of 10 realistic optical corruptions on the ImageNet classification. The proposed complex 11 corruption kernels are direction and wavelength dependent and include chromatic 12 aberration, which are all to be expected in realistic scenarios such as autonomous 13 driving applications. Our experiments on twelve different DNN models show sig-14 nificant differences of more than 5% in the top1 classification error, when compared 15 to the model performances on matched ImageNet-C blur kernels.